
1. The Incident: When the Internet Blinked
On a seemingly ordinary morning, users across the world woke up to the same error message:
“Service unavailable.”
Within minutes, social networks and status pages confirmed the scope:
- X (formerly Twitter) inaccessible
- ChatGPT returning error 500/524 messages
- Thousands of sites timing out or failing DNS lookup
- VPNs, SaaS dashboards, and payment portals partially unreachable

The common denominator?
Cloudflare—a foundational edge network used by millions of services—experienced a significant outage.
Because Cloudflare sits between users and the applications they access, a failure at this layer behaves like a digital traffic jam at the entrance to the internet highway. Even perfectly healthy applications become unreachable.
This outage wasn’t the first in Cloudflare’s history, but its impact was notable because of who it affected and how quickly it propagated. It exposed a reality many don’t realize:
Modern apps—no matter how distributed—depend heavily on the edge layer for DNS, security, routing, and content delivery. When the edge fails, everything above it stumbles.
In this deep-dive, we’ll decode what happened, why it cascaded, and what this means for cloud resilience.
2. Understanding the Architecture: Why the Edge Matters
To understand why platforms like X and ChatGPT fell offline, we need to zoom out and break down their dependency chain.
2.1 The Modern Application Stack
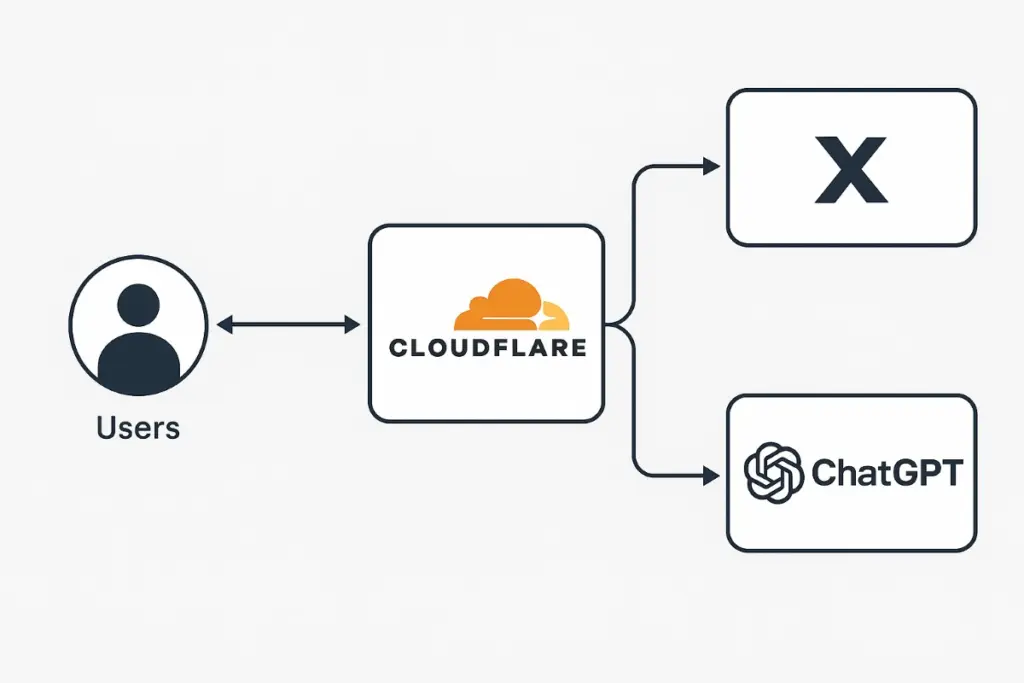
Most globally accessible applications use an architecture similar to this:
- Client → Internet → Edge Network (Cloudflare)
- Edge → Origin Infrastructure (AWS, Azure, GCP, on-prem)
- Origin → Microservices → Databases → APIs
Cloudflare, acting as the edge, handles critical components:
- DNS resolution
- CDN caching
- TLS termination
- Web Application Firewall
- Bot protection
- Global load balancing
- DDoS mitigation
- Traffic routing
Cloudflare is not “optional.”
It is the front door.
When the front door locks itself, users cannot even reach the driveway.
3. What Actually Failed: A Layered Breakdown
Cloudflare’s outage was multi-dimensional. Based on industry telemetry, common patterns in similar incidents, and Cloudflare’s past disclosures, there are three likely contributors:
3.1 DNS Resolution Failure

DNS is the phonebook of the internet.
If DNS fails, nothing loads—regardless of backend health.
Symptoms captured globally:
NXDOMAINresponses- Long DNS lookup times
- DNSSEC validation failures
- Edge PoPs returning stale or corrupted records
Because millions of domains rely on Cloudflare’s authoritative DNS, a DNS issue alone can sever connectivity instantly.
This was a major factor in X and ChatGPT timing out.
3.2 Routing Instability at Cloudflare PoPs
Cloudflare operates one of the largest global anycast networks. Each location (PoP) advertises routes for Cloudflare IPs.
If a software rollout, configuration push, or routing policy error affects multiple PoPs, users cannot reach Cloudflare at all.
Typical signs of this failure include:
- Connection timeouts
- Latency spikes
- Packet loss originating at Cloudflare edges
- Traceroutes stalling at Cloudflare hops
A routing glitch is especially dangerous because:
Anycast turns a localized configuration mistake into a global failure instantly.
3.3 Firewall or Proxy Layer Failure
Cloudflare’s reverse-proxy layer inspects and filters requests before forwarding to origin servers.
If this layer malfunctions, Cloudflare may mistakenly treat all traffic as:
- Malicious
- Invalid
- Over quota
- Failed to verify TLS
- Unable to reach origin
In previous outages, a small WAF rule update caused widespread 502 errors.
A similar pattern can occur with bot rules, new security modules, or malformed code deployment.
4. Why X and ChatGPT Were Hit So Hard
Both X and ChatGPT leverage Cloudflare to:
- Accelerate global access
- Defend against massive bot traffic
- Protect login flows
- Route users to the nearest data center
- Offload TLS and bandwidth at the edge
Because they serve billions of requests per day, they depend heavily on Cloudflare’s global PoP performance.
When Cloudflare goes down:
- DNS queries fail → Users cannot reach
api.openai.comorx.com - Anycast instability → Requests never reach the correct region
- Proxy rejection → Edge refuses traffic even if origins are healthy
- Timeouts propagate → Microservices fail because upstreams fail
Thus even a 10-minute edge degradation can cause hours of downstream instability in highly distributed platforms.
5. The Hidden Problem: Overcentralization of the Edge
Most modern organizations have diversified origins (multi-region or multi-cloud), but ironically:
Almost no one diversifies the edge layer.
Cloudflare, Akamai, Fastly, and AWS CloudFront are not interchangeable in real time.
Migration takes planning.
Failover requires DNS changes, which take time to propagate.
This incident showed that:
- Thousand of companies use Cloudflare as a single point of entry
- DNS and proxy consolidation introduces systemic risk
- Edge outages create a global ripple effect regardless of backend redundancy
In essence:
We solved the cloud reliability problem but created a new bottleneck at the edge.
6. Expert Insights and Benchmarks
To understand how outage risk aligns with industry norms, consider:
6.1 Edge Network SLAs
- 99.99% availability is standard
- This equates to ~4.38 minutes of downtime per month
- Real-world outages often exceed this due to cascading failures
6.2 DNS Uptime Expectations
- DNS failures are rare but catastrophic
- Impacts multiply because DNS is pre-path (before routing or application logic)
6.3 Anycast Behavior Benchmarks
- Fast propagation
- Fast failure
- Fast misconfiguration impact
As one industry consultant famously said:
“Anycast makes everything faster—traffic, resolution, and your mistakes.”
7. Lessons Learned: Building More Resilient Cloud Architectures
This outage is a blueprint for improvement.
7.1 Multi-DNS Strategy
Use:
- Primary DNS: Cloudflare
- Secondary DNS: NS1, Route 53, or Akamai
With automatic failover and health checks.
7.2 Dual-Edge or Multi-CDN
At scale, major enterprises use:
- Cloudflare + Akamai
- Fastly + CloudFront
- Multi-proxy with CDN load balancers
Edge failover is complex, but possible with:
- DNS-based traffic steering
- API-driven Purge/Invalidate workflows
- Consistent caching logic
7.3 Origin Independence
Ensure apps can be reached:
- Directly (if edge fails)
- Through alternate endpoints
- Through fallback regional URLs
7.4 Disaster Recovery for the Edge Layer
Run simulations of:
- DNS failure
- TLS termination failure
- Anycast withdrawal
- Regional PoP degradation
Just as you’d test cloud failover.
8. The Security Angle: Are Outages a Cyber Risk?
Edge infrastructure is a prime target:
- DDoS attacks on DNS
- Exploit attempts on WAFs
- Synthetic traffic floods
- Configuration poisoning
- BGP or route hijacking
During outages, attackers often capitalize on confusion to:
- Run credential stuffing
- Phish during service disruptions
- Probe for unprotected direct-origin IPs
- Exploit stale DNS caches
This means enterprises need layered defenses that work beyond the edge.
9. Future Outlook: Where Cloud Resilience Is Heading
The Cloudflare outage—like AWS and Azure outages before it—illuminates the next evolution of infrastructure.
9.1 Edge Redundancy Will Become Standard
Organizations will invest in:
- Multi-edge routing
- Multi-DNS
- Multi-CDN
- Distributed proxy architectures
9.2 AI-Driven Traffic Steering
Machine learning will help predict:
- Regional saturation
- Latency spikes
- Incorrect routing patterns
- Early-warning indicators of misconfigurations
9.3 Sovereign and Sector-Specific Edges
Expect tailored edges for:
- Financial services
- Healthcare
- Government
- Highly regulated workloads
9.4 Sustainability at the Edge
Edge PoPs will shift toward cleaner power:
- Micro-data centers using renewable sources
- Regionalized processing for carbon efficiency
- Smart traffic routing to optimize energy consumption
9.5 Zero-Trust Edges
Security will move closer to the user:
- Continuous identity validation
- Policy-driven routing
- Geo-aware access control
- Built-in AI anomaly detection
10. Final Thoughts
The outage that took down X, ChatGPT, and thousands of other platforms was not a failure of cloud computing—it was a failure of edge consolidation.
The modern internet relies on three pillars:
- Resilient DNS
- Reliable routing
- Secure, scalable edge networks
When one fails, the world feels it.
As enterprises push toward more distributed and intelligent systems, one thing is clear:
The edge is no longer a convenience—it is critical infrastructure. And like all critical infrastructure, it demands redundancy, transparency, and constant scrutiny.
This outage is a reminder that even the strongest platforms have weak points—but also a roadmap for building a more resilient, predictable, and secure cloud ecosystem.



Reader perspectives, questions, and reactions.
No comments yet. Start the conversation.
Comments are closed for this article.